Long Wu´s and short wu´s, but why?
Message boards :
Number crunching :
Long Wu´s and short wu´s, but why?
Message board moderation
| Author | Message |
|---|---|
 Aurel AurelSend message Joined: 25 Feb 13 Posts: 216 Credit: 9,899,302 RAC: 0 |
I have a little question. I have computed some wu´s for NF@h, and I saw that some wu´s run over 3 hours and other only 30 minutes, or less. (for examble: one wu´s was computed in 6 1/2 Minutes) But why is it so? |
|
Eric Driver Send message Joined: 8 Jul 11 Posts: 1465 Credit: 1,274,673,189 RAC: 1,707,176 |
I have a little question. That's because we break the search space up into equal volumes. Some pieces just happen to take longer to compute. At the core of the algorithm is some factoring of very large integers and this can be unpredictable (depends on the prime factors). So it is impossible to know a priori how long an individual piece will take, and our best option is to take pieces of equal volume. Eric |
|
Send message Joined: 19 Aug 11 Posts: 45 Credit: 1,014,069 RAC: 0 |
Sort of related question ... Which type of WU is most useful to the project if any? At the moment I run both bounded and 'ordinary', I assume unbounded, ones, but would happily run just one type if it was better for the project :) Oh, regarding length, for the OP, noticed the the bounded ones always run for some time, albeit short, but at least they run for a while. The unbounded ones either last less than a second of half a day on my dinosaur machines. Cheers, Al. |
|
Eric Driver Send message Joined: 8 Jul 11 Posts: 1465 Credit: 1,274,673,189 RAC: 1,707,176 |
Sort of related question ... Hi Al, I haven't heard from you in a while. Good to see you're still around. I would say the "ordinary" ones have a higher priority. But the bounded fields are still interesting, and will allow us to fill in some holes in the table of minimum discriminant decics. I would suggest the bounded app for those users who have "dinosaurs" and want to be able to process WUs in a reasonable amount of time. Eric |
|
Send message Joined: 19 Aug 11 Posts: 45 Credit: 1,014,069 RAC: 0 |
I'm always around on BOINC. Been clocking up milestones and badges all over the place, as was my way of BOINCing. Decided this year just to concentrate on a few projects that I like and totally drop the dull ones. So, I'll be around here for a while, got a 500k credit milestone and an upgraded badge to get at least :) Cheers, Al. p.s. Still feeding the dinosaurs a mixed diet of WU types. Think I'll go for the 'ordinary' ones only shortly as they are priority. |
|
Send message Joined: 11 May 13 Posts: 3 Credit: 10,000,508 RAC: 0 |
WOOT! Just got a completed and validated (unbounded) WU worth a grand total of 0.00 credits. How many of these do I need in order to get a badge? http://numberfields.asu.edu/NumberFields/workunit.php?wuid=2592953 So does anyone know the distribution of short, medium, and long WUs there are. Is there some underlying mathematics that can figure this out? My computer has a WU distribution of 50% under 5 seconds, 10% around 14k seconds, and 40% around 25k seconds. |
|
Eric Driver Send message Joined: 8 Jul 11 Posts: 1465 Credit: 1,274,673,189 RAC: 1,707,176 |
WOOT! Well, I wouldn't be too upset, since it was less that 1 sec of cpu time. I expect your sample space is relatively small, because those percentages don't look right. I myself don't see the ultra-fast ones very often (wish I did). What I will do is make a histogram of the runtimes of the WUs that have been returned so far (almost 450k) and that should give us a very accurate distribution of the runtimes. Might take a few days before I get the time, but I will post the results here. Regarding a mathematical explanation, there might be one. I just don't have the time to investigate it. One thing I have noticed is that the fast WUs come in packets (i.e. sequential WUs). That's because they come from adjacent regions in the search space. So the question becomes, why are there fast pockets within the search space? Think if this search as finding the proverbial needle in a haystack; our haystack happens to have pockets of air inside of it. |
|
Aurel Send message Joined: 25 Feb 13 Posts: 216 Credit: 9,899,302 RAC: 0 |
0,00 credits, :) nice, but here is anythink possible. ;) Once, I had an Wu how runs over 21 houres, more than 600 credits, thats was realy cool... :) I´m only running Bounded app, they are stable from the runtimes and shorter. (than normal app) |
|
Eric Driver Send message Joined: 8 Jul 11 Posts: 1465 Credit: 1,274,673,189 RAC: 1,707,176 |
Here are some histograms showing the distribution of run times. I can conclude that 35% of all WUs are of the very fast variety (<10sec). It's hard to draw any definitive conclusions from the rest of the distribution. Part of the problem here is the huge variety of different host speeds. If I analyzed results from a specific host, I suspect I might see a more meaningful distribution and I suspect different hosts would give similar distributions, but shifted in time. Anyways, that kind of analysis would take much more time than I currently have. 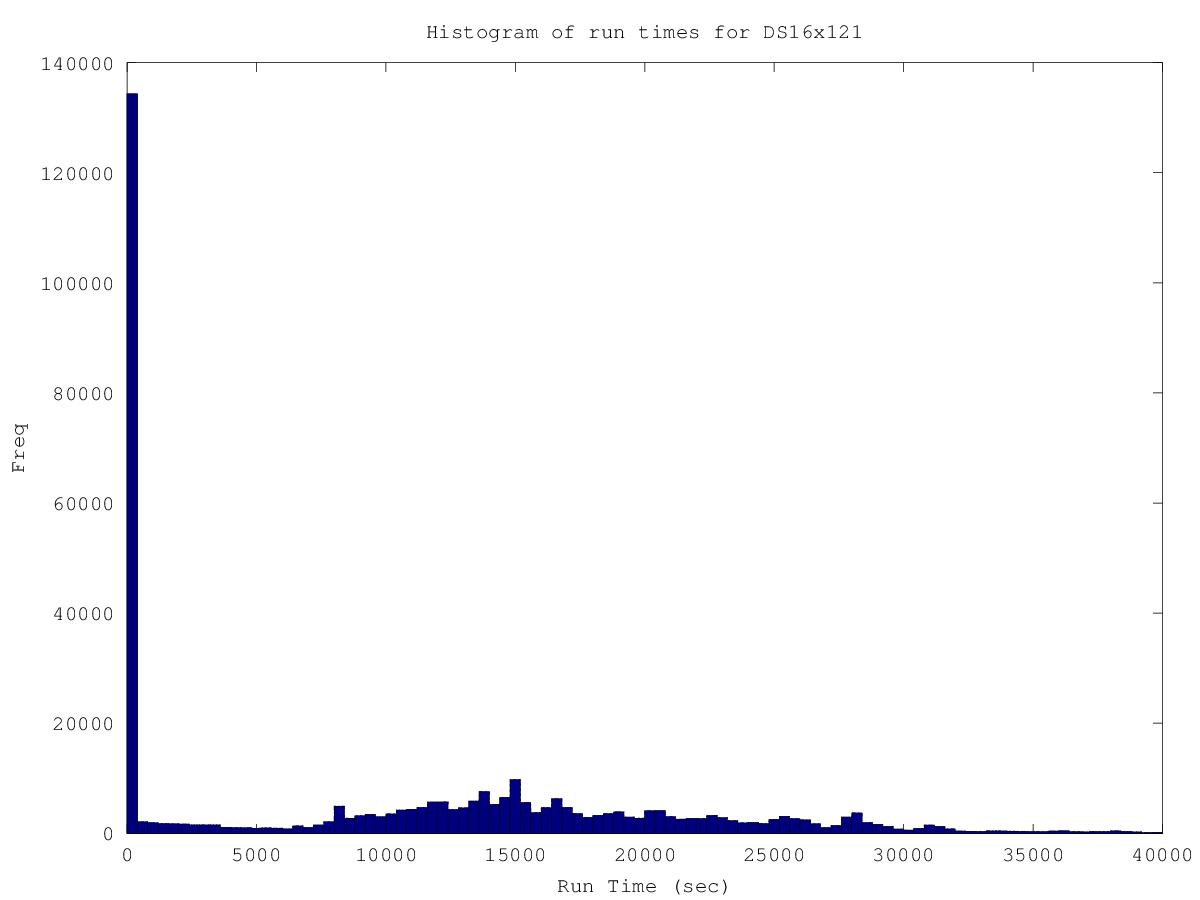 The next histogram ignores the very fast WUs: 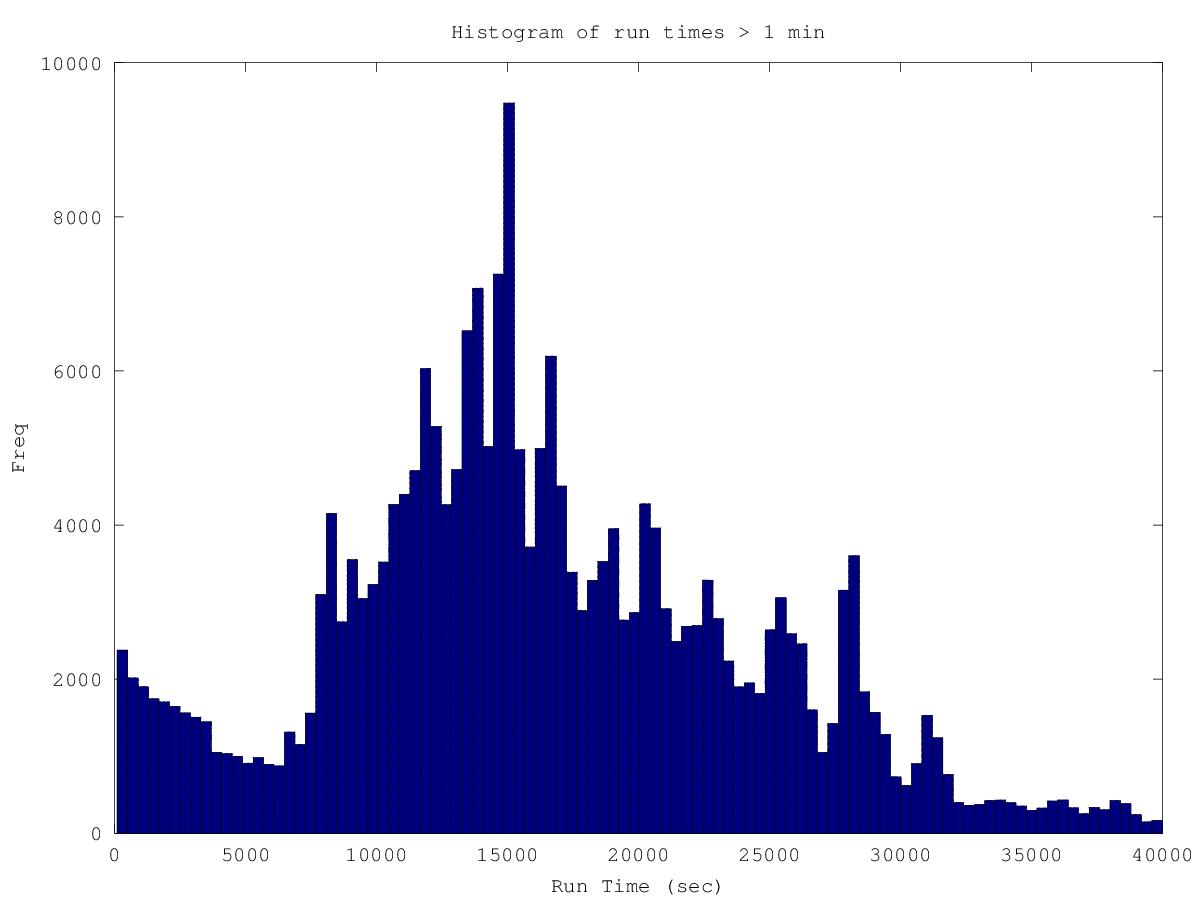 |
|
Send message Joined: 11 May 13 Posts: 3 Credit: 10,000,508 RAC: 0 |
The histogram are great, thanks. It is interesting that so many of the tasks are so short. Sorry to get you into the run times, yeah those would vary by machine. I believe that boinc gives an estimated credit which loosely translates into computational effort (as well as being relatively machine independent). Perhaps a histogram of this would be more interesting. (No need to do it, just puting my thoughts out there). |
|
Send message Joined: 1 Feb 12 Posts: 5 Credit: 15,339,748 RAC: 0 |
According to the histogram, an important proportion of workunits finishes in no time, so why not set up a filter before generating them? Just put them up on the application, run them for 10 seconds, and this can be done on a seperated machine. This may take some time, but for example, for 819200 workunits, you need about 10 days on a good 8 core server. It will also save some bandwidth by sending out less workunits. But since your project is running smooth all along, I think my proposal is moot. I still remember that saying: if it ain't broke, don't fix it. Cheers, fwjmath. |
|
Eric Driver Send message Joined: 8 Jul 11 Posts: 1465 Credit: 1,274,673,189 RAC: 1,707,176 |
According to the histogram, an important proportion of workunits finishes in no time, so why not set up a filter before generating them? Just put them up on the application, run them for 10 seconds, and this can be done on a seperated machine. This may take some time, but for example, for 819200 workunits, you need about 10 days on a good 8 core server. It will also save some bandwidth by sending out less workunits. I have thought about doing that. In fact, I do that exact same thing for the bounded app, where more than 50% of the WUs are very fast. It's a little bit of a pain to setup and it takes up system resources. If bandwidth ever becomes a real issue, then I will definitely do it. Eric |
Copyright © 2026 Arizona State University